Challenges: High-Quality Data Scarcity and Joint Training Competition
Training a unified model for video-to-audio (V2A), text-to-audio (T2A), and joint video-text-to-audio (VT2A) generation offers significant flexibility but faces critical, underexplored challenges. In this paper, we identify two foundational problems:
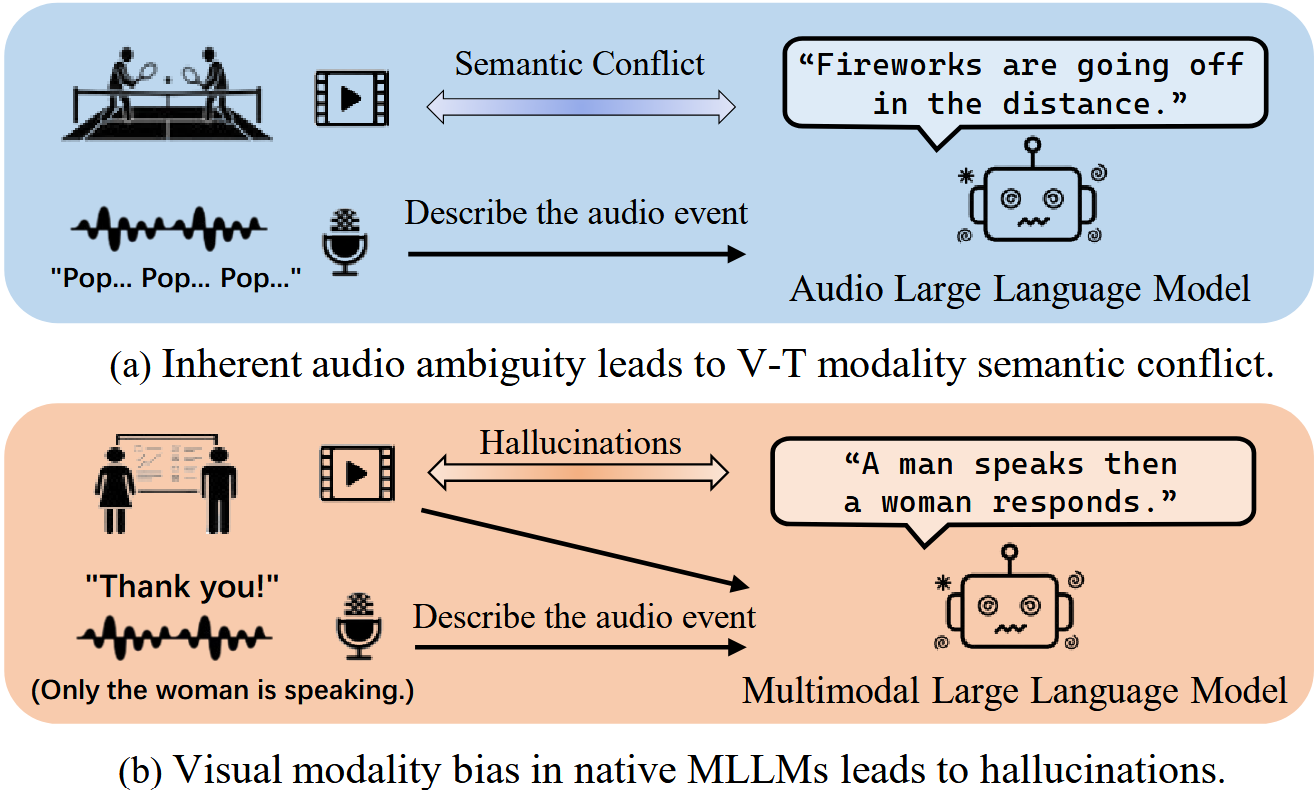
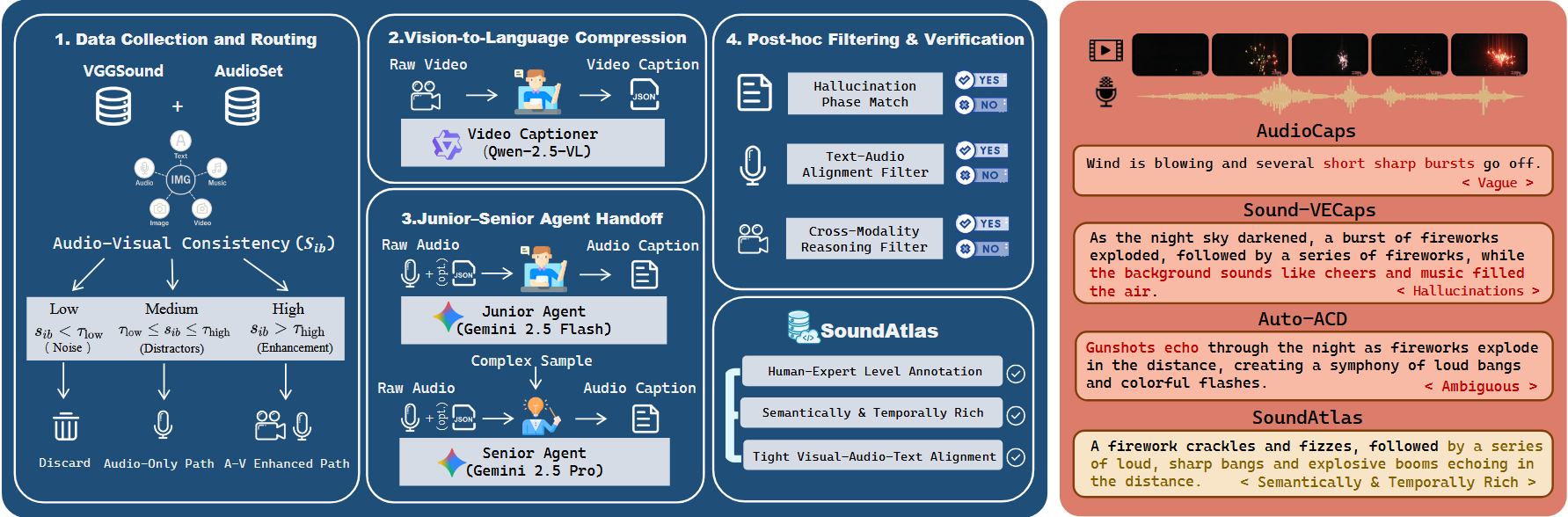
- Data Scarcity and Semantic Conflict (Figure 1): The scarcity of high-quality captions with tight Audio-Visual-Text (A-V-T) alignment leads to severe semantic conflicts. Reliance on audio-only captions introduces ambiguity (e.g., confusing "fireworks" with "tennis hits"), leading to severe semantic conflict between video and text conditions. Conversely, native multimodal models suffer from visual bias, often hallucinating silent objects or ignoring off-screen sounds. These mismatches cause unstable convergence and degraded faithfulness.
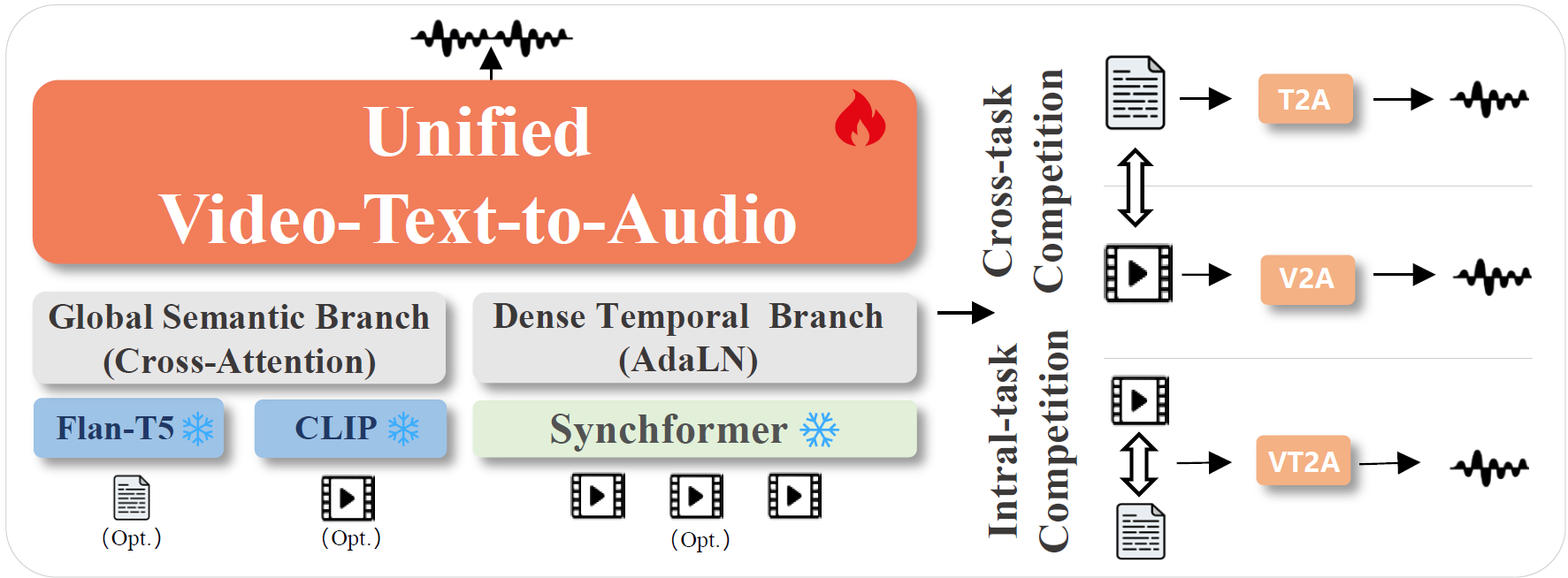
- Cross-Task and Intra-Task Competition (Figure 3): Joint training triggers complex competitive dynamics. Cross-task competition manifests as an adverse performance trade-off between V2A and T2A due to modality heterogeneity, hindering joint optimization. Intra-task competition within VT2A creates modality bias: text bias compromises audio-visual synchronization, while video bias degrades faithfulness in off-screen scenarios like background music.